









Why Smart Factories Are Investing in Industrial IoT Predictive Maintenance in 2026
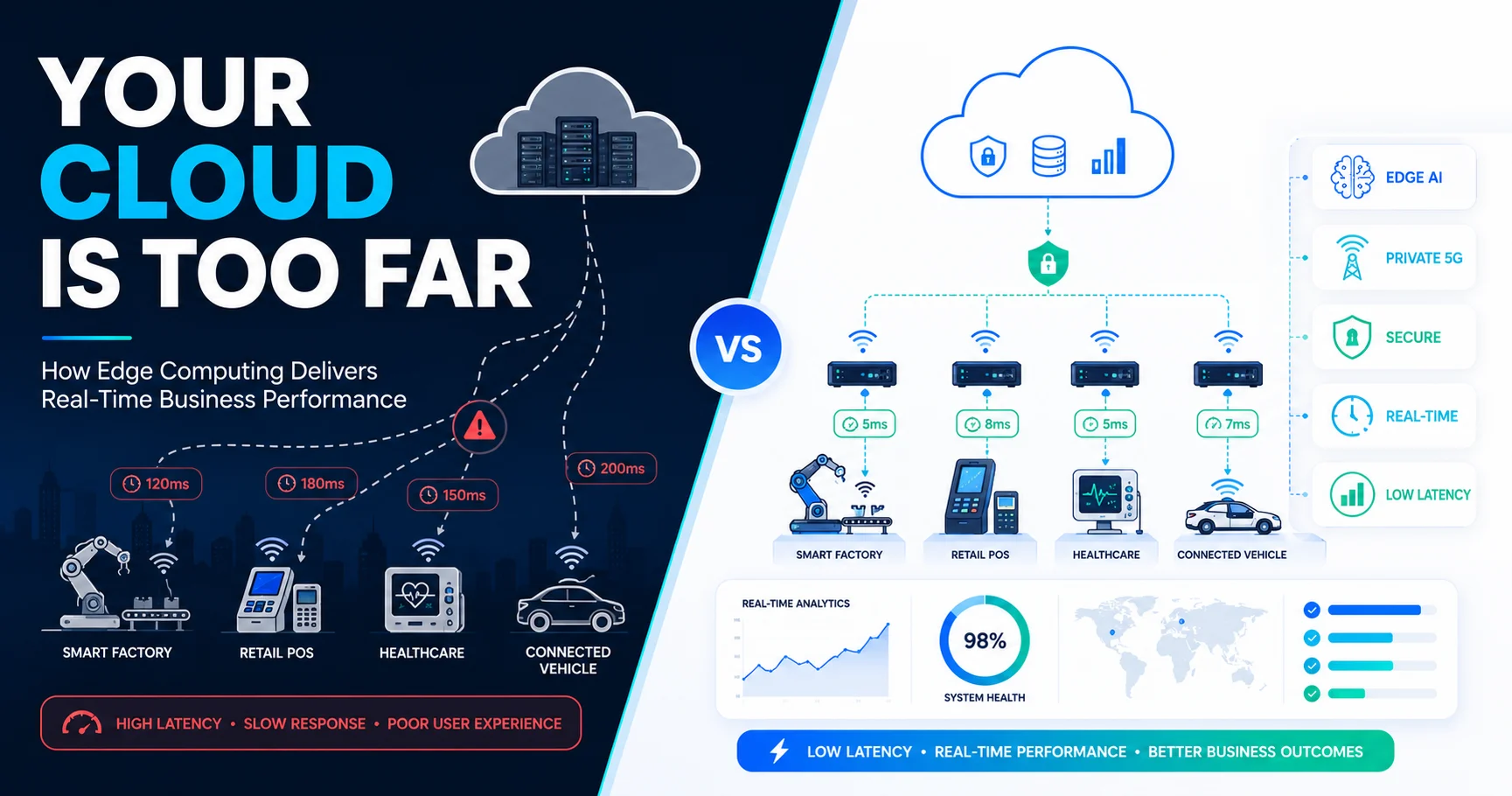
Key takeaways: IIoT predictive maintenance identifies equipment failures before breakdowns occur by analyzing real-time machine data. Industrial IoT solutions combine sensors, edge computing, cloud platforms, and analytics to create smarter maintenance workflows. Predictive maintenance can meaningfully reduce unplanned downtime, extend equipment lifespan, and optimize maintenance resources. Manufacturers are adopting IoT-based predictive maintenance as a core Industry 4.0 strategy for productivity and competitiveness. Successful IIoT implementation depends on strong cybersecurity, data governance, system integration, and scalability planning. What Is Industrial IoT Predictive Maintenance? Industrial IoT predictive maintenance is a data-driven maintenance approach that uses connected sensors, industrial IoT (IIoT) platforms, AI analytics, and machine learning models to monitor equipment health and predict failures before they occur. Unlike traditional maintenance methods that rely on fixed schedules or reactive repairs, IIoT predictive maintenance enables manufacturers to perform maintenance only when machine data indicates a potential issue, reducing downtime, improving asset reliability, and lowering operational costs. Why Predictive Maintenance Has Become Critical for Modern Manufacturing Unplanned downtime is one of the most expensive problems a manufacturing business can face. A single machine failure on a production line can halt output, delay shipments, inflate labor costs, and put customer relationships at risk. For plants running on thin margins, even a few hours of unexpected downtime a month can quietly erode annual profitability. For decades, manufacturers relied on two maintenance philosophies. Reactive maintenance waits for something to break, then scrambles to fix it — usually at the worst possible time. Preventive maintenance tries to get ahead of failures by servicing equipment on a fixed calendar, but this often means replacing parts that still have useful life left, or missing problems that don't follow a predictable schedule. Industrial IoT is changing that equation. By connecting machines through sensors, real-time monitoring, and AI-powered analytics, manufacturers can now understand exactly how their equipment is behaving at any given moment — not just guess based on a maintenance calendar. This shift, from reacting to failures, to scheduling around them, to actually predicting them, sits at the center of the broader Industry 4.0 movement toward connected, intelligent manufacturing. Businesses that invest early in End-to-End IoT Application Development Services are positioning themselves to compete on reliability and efficiency in ways that reactive plants simply cannot match. What Is Industrial IoT Predictive Maintenance? A Closer Look At its core, industrial IoT predictive maintenance is a strategy where machines are connected through IoT sensors and communication networks to continuously collect operational data. That data is then processed with analytics, AI, and machine learning algorithms to spot abnormal patterns and flag potential failures long before they actually happen. The difference between the three major maintenance approaches becomes clear when you compare them side by side: Maintenance Type Approach Limitation Reactive Maintenance Repair after failure Causes unexpected downtime Preventive Maintenance Scheduled servicing May replace healthy components unnecessarily Predictive Maintenance Data-driven prediction Requires connected infrastructure Predictive maintenance directly improves several areas of plant operations at once: equipment availability goes up because failures are caught early, maintenance planning becomes more accurate because it's based on real conditions rather than guesswork, production efficiency improves because fewer lines sit idle, and asset lifecycle management gets easier because teams finally have visibility into how machines are actually aging. How Industrial IoT Enables Predictive Maintenance Predictive maintenance doesn't happen because of a single piece of technology — it's the result of several layers working together, from the sensor on the machine floor all the way up to the AI model making a prediction. 1. Industrial IoT Sensors and Data Collection Everything starts with sensors installed directly on equipment. These devices continuously capture operational data such as temperature, vibration, pressure, humidity, energy consumption, acoustic signals, and other machine performance metrics. A practical example: a vibration sensor mounted on a motor can detect subtle changes in vibration patterns that signal early-stage bearing damage — long before that damage would cause a visible or audible problem on the plant floor. 2. Connectivity and Industrial Communication Networks Once data is captured, it needs a reliable way to travel. This happens through wireless industrial networks, Ethernet connections, industrial gateways, and edge devices that link machines to the broader IIoT system. Reliable connectivity is non-negotiable here — a predictive maintenance system is only as good as the data it can actually collect and transmit. Wireless industrial IoT solutions are particularly valuable because they let manufacturers retrofit existing machines with sensors instead of replacing expensive equipment outright, making adoption far more accessible for plants with a mix of old and new assets. 3. Edge Computing and Real-Time Processing Not all data needs to travel to the cloud before a decision gets made. Edge computing processes information locally, right where it's generated, which matters for a few key reasons: it enables faster decision-making, reduces latency, lessens dependency on constant cloud connectivity, and allows machines to respond to conditions in real time rather than waiting on a round trip to a remote server. 4. Cloud Platforms and Data Analytics While edge computing handles immediate, local decisions, cloud platforms take on the heavier lifting — processing large volumes of historical and real-time machine data. Analytics engines running on these platforms identify performance patterns, flag failure indicators, and surface maintenance requirements across an entire fleet of equipment, not just a single machine. 5. AI and Machine Learning for Failure Prediction This is where predictive maintenance earns its name. Machine learning models analyze both historical and real-time data to predict equipment degradation, likely component failures, and even the remaining useful life (RUL) of a given asset. The more data these models are trained on, the sharper their predictions become over time. Building this layer well typically requires dedicated AI application development expertise, since the accuracy of failure predictions depends heavily on how the underlying models are designed, trained, and continuously refined. Key Components of an Industrial IoT Predictive Maintenance System Bringing all of this together requires several components working in sync: Component Purpose Sensors Capture machine conditions IoT Gateway Transfers machine data Edge Computing Processes data locally Cloud Platform Stores and analyzes data AI Models Predict failures Dashboard Provides maintenance insights Each component depends on the ones around it. Sensors are useless without connectivity to move their data. Data is meaningless without analytics to interpret it. And analytics only creates value once it's translated into a dashboard that maintenance teams can actually act on. A well-designed IIoT predictive maintenance system treats these as one integrated pipeline, not a set of disconnected tools. Real-World Applications of IoT-Based Predictive Maintenance Manufacturing Equipment Monitoring Factories are the most common home for predictive maintenance, applied to CNC machines, assembly lines, robotic systems, motors, and pumps. The benefits show up quickly: reduced downtime, higher production output, and better overall machine utilization across the plant. Energy and Utility Management Power plants and utility companies use IIoT solutions to monitor high-value, hard-to-replace assets like turbines, generators, and transformers. Given how costly and disruptive failures in this sector can be, predictive monitoring often pays for itself many times over. Automotive Manufacturing Automotive plants depend heavily on precision and uptime. Predictive maintenance here keeps robotic arms, welding equipment, and broader production systems running smoothly, which matters enormously on lines where a single stalled station can back up an entire assembly process. Logistics and Warehousing Beyond the factory floor, predictive analytics is increasingly applied to automated storage systems, conveyor belts, and fleet equipment — helping logistics operators avoid the kind of unplanned equipment failure that can cascade into missed delivery windows. Manufacturers pursuing this level of connected operations typically need more than isolated tools; they need Smarter Software Development practices that tie sensor data, analytics, and business systems together into one coherent platform. Business Benefits of Industrial IoT Predictive Maintenance Reducing Unplanned Downtime Unexpected breakdowns are among the costliest events in manufacturing. IIoT predictive maintenance flags problems early, giving teams the ability to plan interventions instead of scrambling to react. Lower Maintenance Costs Organizations that adopt predictive maintenance typically see a drop in emergency repair expenses, wasted spare parts, and unnecessary labor costs tied to over-servicing healthy equipment. Extending Equipment Lifespan Continuous monitoring helps prevent the kind of excessive wear that shortens an asset's useful life, improving long-term utilization of every machine on the floor. Improving Operational Efficiency Real-time insight into machine health lets businesses fine-tune production processes rather than working around unpredictable equipment behavior. Better Decision-Making Through Data Maintenance teams shift from relying on assumptions and tribal knowledge to making decisions backed by actual operational data. Supporting Industry 4.0 Transformation Predictive maintenance isn't just a standalone upgrade — it's one of the foundational building blocks of the smart factory model that Industry 4.0 is built around. Predictive Maintenance vs Traditional Maintenance: Key Differences Factor Traditional Maintenance IIoT Predictive Maintenance Decision Making Manual Data-driven Failure Detection After issue occurs Before failure Monitoring Periodic Continuous Cost Control Reactive expenses Optimized spending Data Usage Limited Real-time analytics The pattern across every row is the same: traditional maintenance reacts, while IIoT predictive maintenance anticipates. That single shift is what drives most of the cost and reliability gains manufacturers report after adoption. Challenges in Implementing Industrial IoT Solutions 1. Integration With Existing Equipment Most factories run a mix of new and legacy machines, and older equipment wasn't built with connectivity in mind. The practical solution is to retrofit sensors, use IoT gateways to bridge the gap, and roll out implementation gradually rather than all at once. 2. Cybersecurity Risks Connecting industrial systems to networks and the cloud introduces new attack surfaces. Manufacturers need to think seriously about network security, access control, data encryption, and ongoing monitoring — because in industrial environments, a cyberattack doesn't just risk data, it can risk physical operations. 3. Data Management Complexity Industrial environments generate enormous volumes of sensor data, and without a clear data governance strategy, storage plan, and analytics infrastructure, that data can quickly become more of a burden than an asset. 4. Lack of Skilled Workforce Successfully running an IIoT predictive maintenance program requires expertise across IoT, cloud infrastructure, AI, and industrial automation — a combination of skills that many manufacturing organizations are still building internally. Staying current with AI trends is a useful starting point for teams trying to close that knowledge gap. Cybersecurity Considerations for IIoT Predictive Maintenance Because industrial systems now sit at the intersection of IT and physical operations, cybersecurity has to be treated as a core design requirement, not an afterthought. That means building in secure device authentication from day one, encrypting data both in transit and at rest, segmenting networks so a breach in one area can't spread unchecked, running regular vulnerability assessments, and staying aligned with relevant compliance requirements for your industry. The stakes here are higher than in typical enterprise IT: an attack on a connected industrial system can disrupt physical production, damage equipment, or create safety risks on the plant floor — not just expose data. How to Implement an Industrial IoT Predictive Maintenance Strategy Step 1: Identify Critical Assets Start with the machines causing the most pain — the ones responsible for production bottlenecks, high maintenance costs, or frequent failures. These offer the fastest return on a predictive maintenance investment. Step 2: Define Data Requirements Determine which sensors you actually need, how frequently data should be collected, and which performance indicators matter most for the assets you're monitoring. Step 3: Deploy IIoT Infrastructure Roll out the sensors, gateways, and connectivity solutions needed to get reliable data flowing from the plant floor. Step 4: Build Analytics and Prediction Models Layer in AI, machine learning, and predictive analytics to turn raw sensor data into actionable failure predictions. Step 5: Monitor, Optimize, and Scale Begin with a pilot on a small set of assets, refine the approach based on real results, and expand across additional equipment and facilities once the model proves itself. Future of Predictive Maintenance With AI and Industrial IoT Predictive maintenance is still evolving, and several trends are already shaping what comes next: AI-powered autonomous maintenance systems that can schedule and even initiate their own interventions, digital twins that simulate equipment behavior before problems occur in the physical world, early movement toward self-healing factories, real-time operational intelligence dashboards, and a growing shift toward edge AI that pushes even more decision-making closer to the machine itself. Interestingly, the underlying approach behind predictive maintenance — using connected data and AI to anticipate problems before they occur — is showing up well beyond manufacturing. The same principles are already being applied in fields like Predictive Analytics in Personalized Healthcare, where early signal detection is just as valuable for patient outcomes as it is for factory uptime. How Businesses Can Choose the Right Industrial IoT Solution Provider Not every technology partner is equipped to handle the full complexity of an industrial IoT predictive maintenance rollout. When evaluating providers, look closely at their track record of industry experience, their depth of expertise in IoT architecture, how seriously they treat security practices, whether their solutions are built to scale across multiple facilities, how well they handle integration with your existing systems, and the strength of their AI analytics capabilities. A provider that's strong in one area but weak in the others will leave gaps that eventually surface as operational problems. Building Smarter, More Reliable Industrial Operations With IIoT Industrial IoT predictive maintenance is becoming less of a competitive advantage and more of a baseline expectation for manufacturers that want higher reliability, lower costs, and stronger long-term competitiveness. By combining connected devices, AI analytics, cloud platforms, and real-time monitoring, businesses can move away from reactive repairs and toward genuinely proactive decision-making. The manufacturers that come out ahead in the next decade will be the ones that learn to treat machine data not as an operational byproduct, but as a real asset — one that tells them what's about to happen, not just what already did. Ready to build a scalable industrial IoT solution for your business? Partner with experienced engineers to design, develop, and implement an IIoT predictive maintenance strategy tailored to your operational goals. table { width: 100%; max-width: 100%; border-collapse: collapse; margin: 24px 0; font-size: 15px; line-height: 1.6; background: #ffffff; border: 1px solid #d9e2ec; display: block; overflow-x: auto; overflow-y: hidden; white-space: nowrap; -webkit-overflow-scrolling: touch; border-radius: 10px; } table tbody { display: table; width: 100%; } table th { background: #0b2a4a; color: #ffffff; font-weight: 700; text-align: left; padding: 14px 16px; border: 1px solid #0b2a4a; } table td { padding: 13px 16px; border: 1px solid #d9e2ec; color: #1f2937; vertical-align: top; } table tr:nth-child(even) td { background: #f8fbff; } table tr:hover td { background: #eef6ff; } table p { margin: 0; } /* Mobile Optimization */ @media (max-width: 768px) { table { font-size: 14px; } table th, table td { padding: 12px; } }